Claude Code 30 轮烧掉 545K token,可你亲手打的字只占 2K:拆开账单,九成钱花在「把同一摞历史重发了 30 遍」
2026-06-14
本文适合:① 每天用 Claude Code、好奇它后台到底怎么烧 token 的人;② 想把账单压下来、又看不懂 input/output 为什么这么不对称的工程师;③ 做过后端 / 数据架构、想从结构上理解 cache 为什么能省钱的人。
我做数据架构,平时跟事实表、物化视图、增量 CDC 这些东西打交道。所以第一次翻开 Claude Code 某次任务的 token 账单,我冒出来的念头不是「这模型真贵」,是「这不就是一张静态维度表,被每次查询全表重扫了一遍」。这篇就用这个视角,把 545K 这张账单一项一项拆给你看。
结论先拍在前面:一次 30 轮的 coding 任务烧到 545K input token,可你亲手敲进去的字加起来不到 2K,占比连 0.3% 都不到。这张账单九成不在你打的字上,而在「每按一次 Enter,整摞历史被重新拍一遍发出去」这件事上。 这篇讲清三件事:钱到底花在哪几项、为什么非得这么发、cache 又是怎么把九成开销抠回来的。
先做个选择题。一次 30 轮的任务,你打进去的字不到 2K token,这次任务总共烧了多少 input?三个选项——A. system + tools 这些「基础设施」占大头;B. messages 历史累积越滚越贵;C. 你输入的每一行代码。选一个。多数人选 B,觉得对话越长历史越贵。方向对,但没说到根上:真实账单 545K,其中 99% 烧在「重复运输」上,而被反复运输的,恰恰是那批你从没改过、却每轮都原样背一遍的 system 和 tools。下面把这张账单的三层结构摊开。
一、单看一轮请求,你打的字占不到 3%,剩下 97% 全是每轮重背的基础设施
一句话:拆开任意一轮请求,真正的大头是几样你压根没动过的固定内容。它们任务一开始就定死,却被每一轮原样重发,这才是账单的脊柱。
先看一轮典型的 coding 请求长什么样。你刚写完一行代码,按 Enter 让 Claude 继续,这次请求的 input 构成是:
- system 指令:约 8K token。 角色设定、输出格式约束、工具调用协议、安全规则,外加一长串行为准则。这部分几乎 100% 不变——你改一行注释还是重构整个模块,system 都被原封不动塞进每次请求。
- tools schema:约 6K token。 Claude Code 注册了 5–8 个工具,每个工具的名字、用途、参数 JSON Schema 加起来就是这个数。Read、Write、Bash、Grep 这些,光把「这个工具怎么用」讲清楚就得几千 token,而且 session 内不变——你不会跑到一半突然注册新工具。
- skill metadata:约 3K token。 CLAUDE.md 里定义的技能描述、文件映射、技术栈偏好,任务开始时就固定了。
- messages 历史:约 2K token。 前几轮的对话 + 工具调用结果,只算 messages 数组本身。
- 你的输入:< 0.5K token。 一条短指令,「继续」「解释一下这段」「为什么报 500」。
合计 8K + 6K + 3K + 2K + 0.5K ≈ 19.5K token。你亲手敲的字占比不到 3%,剩下 97% 全是「基础设施」,每轮原封不动重发一遍。
有个误解得当场掐掉:很多人把 messages 当账单大头。其实前十轮里,messages 通常是所有项里最小的一项。后期让它膨胀的,往往不是你的对话,是某一次工具读进来的大块文本。
所以这一轮账单最该盯的不是「我话说多了」,是那几样你从没碰过、却每轮都得背一遍的固定内容。 它们体积大、还每轮都在,正是你最容易忽略、最该下手的地方。
二、把这一轮乘以 30,你才看清账单的真正形状:贵的永远是被运了 30 遍的同一批历史
一句话:单轮的 97% 不可怕,乘以轮数才可怕。历史只增不减,那批固定内容被一字不差地运了 30 遍,账单就这么被「复利」吹起来。
把同一任务跑 30 轮。S01 讲过,history 只增不减,每轮结果都追加到 messages、从不裁剪。30 轮后账单长这样:
- system 指令:8K × 30 = 240K token。 同一份文本,被重复运输 30 次,你一个字没改它。
- tools schema:6K × 30 = 180K token。 同理。
- skill metadata:3K × 30 = 90K token。 同理。
- messages 累积:约 80K token。 每轮新增约 2.5K(你的输入 + 模型回复 + 工具结果),这是唯一真正「增长」的部分,占比只有 13%。
- 工具结果:约 30K token。 30 轮中部分轮有工具返回(读文件、执行代码),每次约 1K。它也属于 messages,但单独列出来,因为它动态、不可预测,还最容易失控。
- 你的输入:约 2K token。 占比不到 0.3%。
六项相加:240K + 180K + 90K + 80K + 30K + 2K ≈ 620K token,其中 99.7% 是被反复运输的同一批历史。一次真实任务量到的累计 input 大约 545K。轮次长短、messages 中途有没有被裁剪,会让这个数在 500K 到 620K 之间浮动,但量级和结论不变:贵的永远是那批被重复运输的基础设施,不是你打的字。
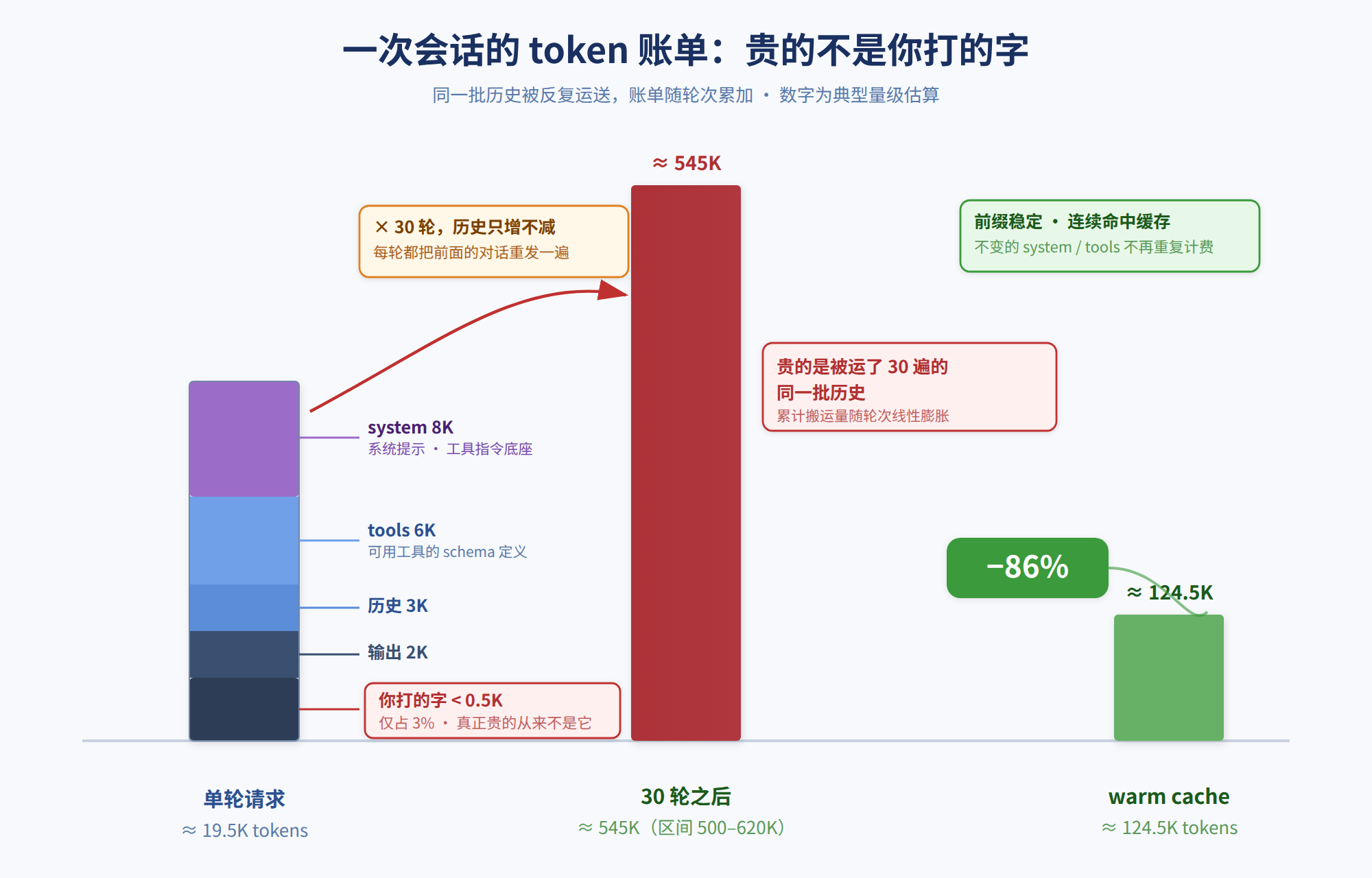
(图 2.1)545K token 账单:1 轮 vs 30 轮 vs cache 后。
这个数字不是我估的,是从 jsonl 里逐轮加出来的
我翻过自己一次 30 轮重构任务的 jsonl,usage 字段里 input_tokens 逐轮累加,加完就是 545K。而 output 反而只有 40K,模型每轮只吐几百到一两千 token,input 是它的 13 倍。input ≫ output 这种极度不对称,是 agent 类应用跟聊天机器人最不一样的地方,也是所有省 token 招式的靶心。
那 30K 工具结果,是账单里最容易爆的一项
它动态、不可预测,还容易失控。你让 Claude 读一个 2000 行的配置文件,这 2000 行(约 10K token)会作为一条 tool_result 永久压进历史,从此每一轮都跟着它重发一遍。一次「随手读个大文件」,可能比你接下来十轮的全部对话加起来还贵。这条会在 S04 的 grep > read_file 里专门拆,这里先记住一句:工具吐回来的东西,进了历史就再也出不去。
复利效应:每一轮的「起步价」都比上一轮高
历史只增不减,第 1 轮 input 不到 20K,第 15 轮可能已经 35K,第 30 轮逼近 50K。你以为第 28 轮只是随口追问一句,后台却把前面 27 轮的全部上下文又运了一遍。任务拖得越长,这条曲线越陡,到后段每按一次 Enter,绝大部分钱都花在「把这本越来越厚的历史重念一遍」上。
三、cache 把九成开销抠了回来,但它救的是「连续作业」,不是「随便点点」
一句话:九成开销看着像浪费,其实是无状态架构的必要代价。prompt cache 就是认下这笔代价之后,把它从 1× 压到 0.1× 的那一手。只是这层便宜有 5 分钟的保质期,前缀一动就作废。
为什么非得无状态、每轮重发?四个工程理由
既然这么贵,Anthropic 为什么不在服务端存 session?
- Scalability。 任何 GPU 节点都能处理任意请求。存了 session,请求就得路由到同一节点——要么引入 sticky session 破坏弹性伸缩,要么跨节点同步状态增加延迟。
- Multi-tenant。 Claude API 处理百万级并发。每个 session 都在服务端存一份 context,内存开销爆炸——一个用户开 10 个 session,每个都几百 K token,服务端存不起。
- 可缓存可复用。 相同的 prefix 永远对应相同的 KV 计算结果(缓存的是前缀那段注意力计算,不是最终采样出来的字,跟模型输出随不随机无关)。上下文藏在服务端会话里,客户端看不见也控制不了,缓存边界就糊了。
- 断线可恢复。 客户端把历史写在本地 jsonl 里,网断了重新读 jsonl、拼请求、再发一次,服务端不用知道之前发生过什么。session 若在服务端,断线重连要重新拉状态,复杂度高一个数量级。
四条连起来看,无状态不是偷懒,是一个经典权衡:用「每次多发一遍历史」的带宽和算力,换来水平扩展、百万并发、可缓存、可恢复这四样。REST 当年战胜有状态 RPC 也是同一个故事——无状态更难省单次开销,但更容易扛规模。所以 30 轮「会话」是客户端制造的虚假状态:每按 Enter,客户端读本机 jsonl → 拼完整请求 → 重发,服务端从 0 重建 context。这就是为什么 system 每轮都要发——服务端根本不知道你之前发过什么。
prompt cache:协议层坚持「全量重发」,计费层偷偷「只算增量」
cache 的原理是:服务端仍要求你全量发送完整请求(协议不改),但会识别请求的 prefix 是否与之前相同。相同就复用算好的 KV cache,只对新内容做增量计算。计费上——首轮写入 cache 时 1.25× 单价(写有开销),后续命中时 0.1× 单价(便宜 10 倍)。
用一个简化模型算一下 warm cache 下 30 轮的等效账单(假设每轮稳定 prefix 取 30K:system 8K + tools 6K + skill 3K + 一段历史 13K):
无 cache: 30K × 30 轮 = 900K (全价 1×)
warm cache:
第 1 轮 写入 cache 30K × 1.25 = 37.5K
第 2-30 轮 命中 cache 30K × 0.1 × 29 = 87K
────────────────────────────────────────────
合计 ≈ 124.5K
省下 (900 − 124.5) / 900 ≈ 86%真实场景里 messages 会逐轮变长、prefix 跟着涨,绝对数字比这个模型大,但「命中按 0.1× 单价、相当于打一折」这个结构是确定的。86% 的成本削减,靠的就是在服务端留一份「仓库副本」,之后只确认「还是老货」而不重发。
这层便宜有保质期:5 分钟 TTL,前缀变一个字节就作废
两个容易忽略的细节。一是 cache 的断点(breakpoint)由 Anthropic 自动放在 system / tools / 第 N 条 message 这些天然边界上,你不用手动标,但你能做的是别让这些边界前面的内容乱动。二是那个 5 分钟 TTL:它从最后一次命中起算,连续敲就一直续期;可你一旦回条微信、改一下 CLAUDE.md、或者干脆换个话题,下次回来 prefix 对不上,整段 cache 作废,单价从 0.1× 弹回 1×。
所以 97% 都在重发,看着像巨大浪费,换个角度它是无状态架构的必要开销,cache 是把它从 1× 压到 0.1× 的杠杆。真正的浪费不是「重发」本身,是「本可以命中却没命中」——每一次不必要的话题切换、每一次手痒去改 system、每一次让会话凉过 5 分钟,都是在主动把 0.1× 的便宜退回成 1× 的全价。想通这层,省 token 的心智模型就从「少发数据」变成了「保护前缀的连续性」。
数据架构师视角:这就是列存 + 增量 CDC,换了个场景
我做数据架构,这套东西看着眼熟得很:
- 无 cache 的请求 = 每轮全表全量重放。 system 是静态维度表,tools 是配置表,messages 是增量日志——但每次查询都把三张表 JOIN 后全量扫描。这是数据仓库 2010 年前的做法,后来被增量更新 + 物化视图取代。
- prompt cache = 给稳定前缀建物化视图。 把 system + tools + skill 预计算好,每次请求只对增量的 messages 做计算。相当于建了个
CREATE MATERIALIZED VIEW context_cache ...,然后每次查询只追加UNION ALL SELECT ... FROM new_messages。 - cache miss = 物化视图失效要重建。 改 CLAUDE.md(skill 变了)、切话题(system 边界后内容变了)、走神 5 分钟(TTL 过期),每次 miss 都相当于 DROP 掉视图重新全量扫描。
这跟列存 + 增量 CDC 的思路一模一样:列存把稳定维度列和动态事实列分开,CDC 只传输增量变更。prompt cache 就是 AI 推理场景下的列存 + CDC。这个视角能直接换成两个旋钮:想省钱,要么提高命中率(让物化视图更久不失效——少改前缀、连续作业),要么缩小增量(让每轮新追加的 messages 更小——少读大文件、及时把旧历史压成摘要)。后面 S03、S04 讲的招,拆开看全在这两个旋钮上做文章,没有第三个旋钮。你看任何「省 token 工具」,第一个问题就该是:它拧的是哪个旋钮?
怎么给自己的账单做体检
翻开任意一条 assistant 消息的 usage 字段,盯三个数:input_tokens、cache_creation_input_tokens、cache_read_input_tokens。cache_read 占比越高,说明你越多吃到 0.1× 的折扣;这个比例长期低于 30%,基本能断定你在频繁切话题或频繁改前缀,每轮都在重写 cache。一行 npx ccusage 就能把最近会话的命中率拉出来,这是体检最快的方式。
三句话收口:
- system + tools 才是真账单,messages 不胖也烧穿。 真贵的是每轮重发那 97% 的基础设施,不是你打字那 3%。
- 30 轮便宜 ≠ 总赢。 cache 的 5 分钟 TTL 一断,一次 miss 就把攒下的 86% 便宜还回去。很多人觉得「Claude 越聊越贵」,其实多半不是越聊越贵,是你越聊越容易在中途触发 miss——cache 省的是连续请求,不是随机请求。
- cache 省的是账单不是思考。 模型每次照样从头算,prompt cache 只复用 KV cache 的计算结果,不改变推理过程。工程优化能省钱,但不会让模型变快变聪明。
缩成一句给自己提醒:省 token 不是少打字,是别让那 97% 的基础设施反复 miss。
收口 + 一个可以打脸的预判
撂一个能被证伪、带时间窗的判断:未来 12–18 个月,Claude Code 这类工具的「单位任务成本」竞争,会明显从「比谁模型便宜」转向「比谁默认就帮你保住前缀」——也就是把 cache 命中率和增量体积这两个旋钮,从「老手手动拧」做进框架默认行为里(自动 compaction、自动把大文件转成引用、自动隔离话题)。谁先把这两件事做成开箱即用,谁的同类任务账单就能稳定低一个量级。我赌得挺死:这跟当年数据库从「手写全表扫描」走到「查询优化器默认建物化视图」是同一条路——最后拼的不是引擎快不快,是默认行为帮没帮用户省。
下集预告:既然账单的命脉是 cache 命中率和前缀稳定性,有哪些招能主动去拨这两个变量?S03 讲 4 个「系统自动生效」的原理级杠杆——Prompt Caching、Context Compaction、Sub-agent 委派、Progressive Disclosure,它们各管一摊,但底层动作是同一个:压住「被重复运输的历史」的体积或频率。
互动题:去 npx ccusage,或翻自己最近一次长会话的 jsonl,把 cache_read 占比报到评论区,我们对比一下谁的前缀保护得最好。我赌占比低于 50% 的人,回看那天多半都干过这几件事:中途改了 CLAUDE.md、切了话题、或者离开太久让会话凉了。
本系列每周两更,跟着拆完,你会对每一次回车背后的开销心里有数。卡在哪个点,评论区告诉我,我挑高频的写进后面几篇。
我是做数据架构的,在公众号「炼丹炉手记」用工程师的较真劲儿实测 AI 工具的真实 ROI——真省钱、真赚钱,还是智商税。工程拆解之外的,都在那边。
本文为 AI 辅助创作。
本文首发于知乎:阅读知乎原文 →