按一次回车,Claude Code 后台跑了 17 步:拆开看就是一个 5 步 while 循环,而烧 token 的根子,是它「历史只增不减」
2026-06-14
本文适合:① 每天按 Enter 用 Claude Code、好奇后台到底在干嘛的人;② 做过后端 / 数据架构、想搞懂 Agent 为什么这么烧 token 的人;③ 在用 Claude / GPT API 却看不懂账单结构的开发者。
我做数据架构,日常打交道的就是 append-only 日志、物化视图、不可变事实表那一套。所以盯着 Claude Code 的后台日志看的时候,我脑子里冒出来的第一句不是「这 AI 真聪明」,是「这不就是一条事实日志在反复重放么」。这篇就拿这个视角,把 Agent Loop 给你拆开。
结论先撂这儿。你按一次回车,后台跑的那一串东西拆开看真不神秘——一个 5 步的 while 循环,不过是多跑了几轮。它好用,我的判断是七成功劳在工程层,不在模型。至于你那张越滚越吓人的 token 账单,结构性的根子其实只有一条设计——历史只增不减。下面就把三件事讲清楚:这循环长啥样、它凭什么烧钱、你真正能动的杠杆在哪。
你以为按下 Enter 就是一步?我在 Claude Code 里敲完一句「帮我把这个 Python 脚本改成分批处理、支持断点续传」,回车,转身去接了杯水。回来一看,终端滚了 17 行日志,文件被改了三次,测试跑了两轮,中间还 grep 了一个配置文件确认参数名。按一次 Enter,后台跑了 17 步。 更要命的是,那个大模型压根不记得我上一句说了啥。HTTP 无状态,服务端不存会话,全靠客户端每一轮把整本历史重发一遍,才骗出了「它记得」的错觉。这 17 步到底是什么、为什么这么烧 token,下面就拆。
一、Agent 不是黑魔法,拆开就是一个 5 步 while 循环
一句话:最小可用的 Agent 就是 组装 → 调 LLM → 解析 → 执行工具 → 追加历史 五步,外面套一个 while。你看到的那几十步「自主操作」,无非是这五步多跑了几轮。别被「Agent」「智能体」这些词唬住,写过三年后端的人都看得懂下面这段伪代码:
while (iter++ < MAX) {
const prompt = build(system, tools, messages); // ① 组装
const response = await llm.call(prompt); // ② 调 LLM
const { text, tool_uses } = parse(response); // ③ 解析
if (!tool_uses) break; // 没有工具调用 → 退出
const results = await Promise.all(
tool_uses.map(t => dispatch(t)) // ④ 执行工具
);
// ⑤ 追加历史:tool_result 必须以 user 角色包装(Anthropic 协议)
messages.push({ role: "assistant", content: response.content });
messages.push({ role: "user", content: results.map(r => ({ type: "tool_result", ...r })) });
}这 5 步,每一步都藏着不显然的细节,但合起来就一件事:把一个失忆的 LLM,缝成一个能连续做事的机器。
- ① 组装 Prompt。 system(固定系统指令)+ tools(JSON Schema 格式的工具描述)+ messages(历史对话)拼成一个巨大字符串丢给 LLM。注意 messages 是「只增不减」的——每轮只往尾部追加,从不删中间条目,跟数仓里的不可变事实表一个样。这一条,是后面所有故事的源头。
- ② 调 LLM。 流式
stream,不是等全部 token 生成完再返回(你看到的打字机效果就是它)。断网或超时要 retry,通常指数退避、最多 3 次。tool_use也不是一整包丢给你,是一个 content block 一个 block 增量推、参数都是一段段 JSON 拼出来的,解析器得边收边拼。 - ③ 解析响应。 结果就两种:一段纯文本,或一个/多个
tool_use。多个可以并行(「先 read 文件 A,再 grep 关键词 B」一起上)。解析失败就把错误响应丢回去,让 LLM 自己修。 - ④ 执行工具。 唯一真正「做事」的一步。
dispatch按tool_use里的 name 找到本地函数执行——文件读写、代码搜索、shell 全在这。Promise.all并发,要读三个文件就一起读,不串行。 - ⑤ 追加历史。 整个循环最关键、也最贵的一步:把 assistant 响应和 tool_result 都追加进 messages。退出条件只有一个——响应里没有
tool_use,模型觉得「做完了」就吐一段纯文本,循环结束。MAX是硬上限,通常 20–30,防死循环。
真实任务,就是这 5 步多跑了 4 轮——正好 17 步
5 步是骨架,真实任务是骨架的多轮展开。还是那个「Python 脚本改分批 + 断点续传」的任务,它的执行轨迹长这样:
- 组装 Prompt(system + tools + 用户问题)
- 调 LLM
- 解析 → 1 个 tool_use:read 脚本文件
- 执行 read
- 追加历史(assistant 响应 + tool_result)
- 组装新 Prompt(历史多了 2 条)
- 调 LLM
- 解析 → 1 个 tool_use:grep 配置文件里的参数
- 执行 grep
- 追加历史
- 组装新 Prompt(历史又多 2 条)
- 调 LLM
- 解析 → 2 个 tool_use:edit 文件 + run test
- 并行执行 edit 和 run test
- 追加历史(仍是 2 条:1 条 assistant + 1 条把两个 tool_result 打包在一起的 user)
- 组装并调 LLM(历史已累积到 8 条)
- 解析 → 纯文本,没有 tool_use,循环退出
前三轮各跑满 5 步(1-5、6-10、11-15),第四轮组装好 prompt、调一次 LLM、解析到纯文本就退出——没有工具执行也就没有历史追加,只剩「组装并调 LLM」和「解析退出」两步(16-17)。15 加 2,正好 17。
这里有个最容易数错的点。每一轮往历史里追加的永远是 2 条消息——1 条 assistant,加 1 条把本轮全部 tool_result 打包在一起的 user。哪怕第三轮一次返回了 edit 和 run test 两个 tool_result,它俩也塞进同一条 user 消息里,算 1 条,不算 2 条。所以历史条数是 2 → 4 → 6 → 8,每轮加 2,跟你这轮调了几个工具没关系。
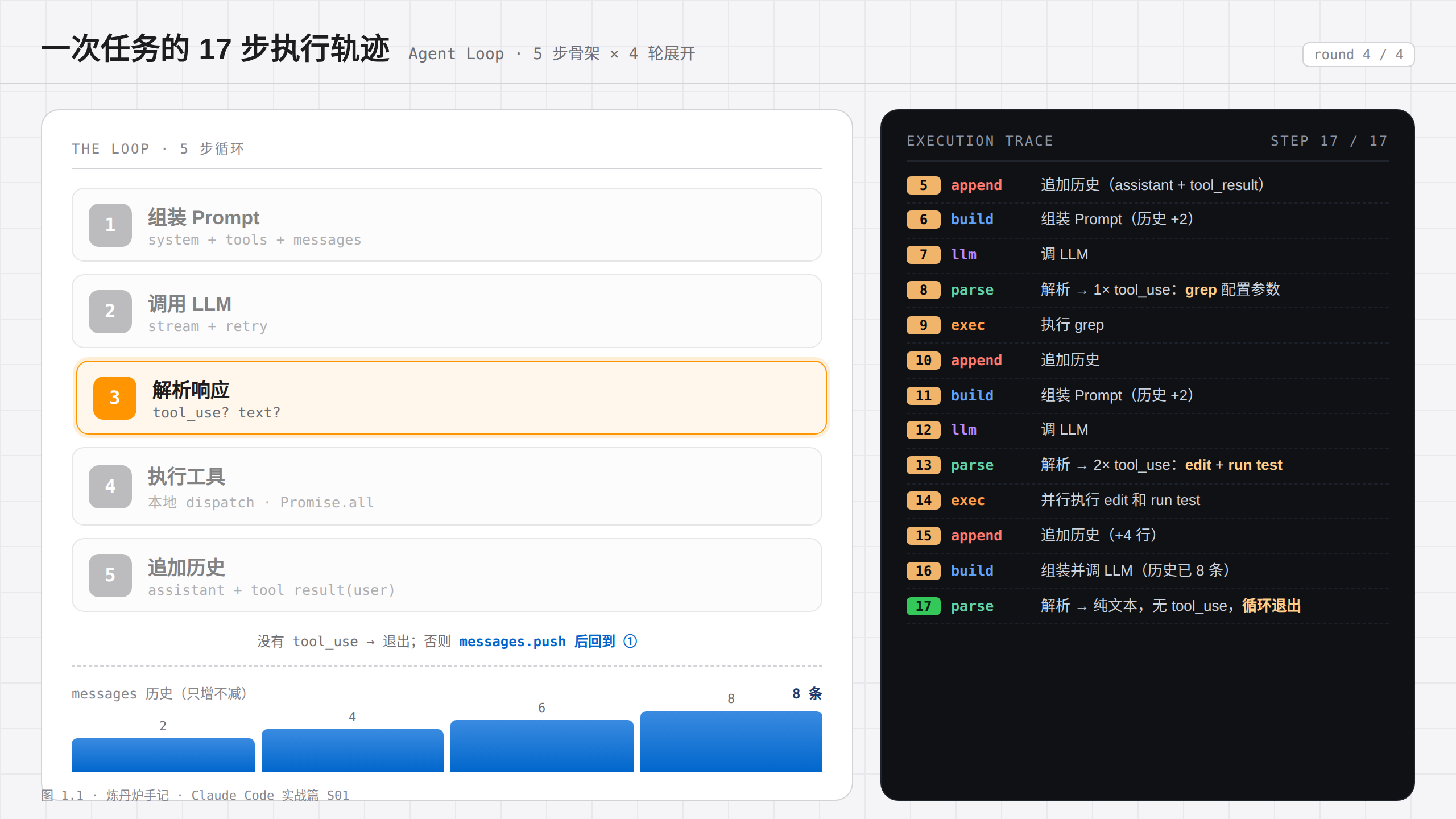
(图 1.1)一次任务的 17 步执行轨迹。左边是 5 步循环的骨架,右边是逐条展开的 execution trace;能清楚看到 4 轮循环、每轮内部的 5 步,以及 messages 历史随每轮往下越堆越长。
二、你的 token 账单,根子在「历史只增不减」这一条
很多人以为 Agent 的三个协议设计——每轮重发历史、tool_result 占 user 角色、历史从不删——是三件独立的事。其实它们是同一条「历史只增不减」的三个侧面,合起来就是你账单结构性变贵的全部原因。一个一个看。
2.1 每轮都把整本历史重发一遍——因为 HTTP 无状态
为什么不能像数据库会话那样,让服务端记住上下文?答案很朴素:HTTP 无状态。Anthropic 的 API 是标准 RESTful 接口,每个请求都独立,服务端不存会话,你不在请求里带上历史,模型就看不到。这不是偷懒,是架构选择——无状态让 API 能水平扩展,任何节点都能处理任何请求;代价就是每次都得把整本历史重发一遍。
这个物理代价直接催生了 prompt caching:服务端在 system、tools、历史前缀这些「几乎不变」的部分打 cache 标记,复用算过的 Key-Value 矩阵,不用每轮从头重算。它不是锦上添花,是止血——没有它,每轮重发整本历史的算力成本谁也扛不住。
关键在它的计费结构。命中时那部分 token 的读取单价只有基础输入价的约 0.1 倍(打一折),但写入 cache 的那一次要贵 25%。 所以只要前缀稳定、连续命中,30 轮重发历史也便宜得离谱。但它有个隐形过期机制:TTL 通常只有 5 分钟,且前缀变一个字节就失效。你切了话题、改了 CLAUDE.md、或者走神 5 分钟回来再敲一句,前缀对不上,这部分就退回全价重算——单价从 0.1 倍跳回 1 倍,差不多是 10 倍的跳变。便宜不是天上掉的,是「前缀别动」换来的。
2.2 工具吐回来的每一行,都跟你打的字一样永久占着历史
Anthropic 的消息协议只有三种角色:system、user、assistant,没有 tool 这种中间角色。所以工具的执行结果必须包装成 user 角色。这意味着工具返回的每一行数据,都跟你亲手敲的字一视同仁,被当作「对话的一部分」永久留在历史里。让它读一个 2000 行的配置文件,这 2000 行就作为一条 user 消息压进历史,之后每一轮 prompt 都带着这 2000 行。
对比一下 OpenAI:它有独立的 tool 角色(早期叫 function),工具返回走 role: "tool",跟 user 分开。Anthropic 没走这条路,好处是协议更简洁(模型眼里只有「谁在说话」),代价是工具输出和用户输入混在同一条流里,你没法在协议层单独给工具输出做裁剪或降权。
这条细节直接养出一个老手习惯:能用 grep 精确定位的,就别整文件 read。少吞 2000 行进历史,等于后面每一轮的 prompt 都跟着瘦一圈。工具用得糙不糙,会一字不差地写进你后面每一轮的账单里。
2.3 历史为什么不删?三条替代路都有副作用
既然历史越滚越长,删一点不行吗?三条路我都替你踩过坑:
- 删旧对话(只留最近 10 轮):模型会失忆。你删掉第 3 轮的「用 Python 3.11」,到第 8 轮它可能就用 3.9 的语法,然后出错。
- 折叠成摘要:会丢细节。第 5 轮说过「某参数默认值是 1024」,摘要里只剩「配置了参数」,第 12 轮模型就不知道这值是多少了。
- RAG 检索:召回率永远不是 100%,你也永远不知道历史里哪句话后面会被引用;K 调大召回是高了,无关片段也跟着多,延迟和 token 又涨回去;更糟的是召回错一条,模型就在错误前提上往下推,比单纯失忆还难排查。
三条路都有副作用,保留原文最稳,token 涨就涨。这个问题的终极解法不是「删历史」,是「压缩历史」——也就是 Compaction,那是 S02 的内容。
把账算到这儿,你会发现一个复利效应。第 1 轮 prompt 可能就一两千 token,但因为历史只增不减,第 4 轮要把前三轮所有响应和 tool_result 一起重发;任务越往后,每一轮的「起步价」越高。你以为第 15 轮只是随口问个小问题,实际上后台把前面 14 轮的全部上下文又重发了一遍。一次几十轮的 coding 任务,光这种重复重发,就能让单次 input 堆到几十万 token。
三、想省 token,真正能动的只有两个杠杆:前缀稳定性 + 历史增长速度
把 Agent Loop 翻译成数据工程的语言,省 token 的杠杆就一目了然。它根本不是「少打字」,而是控制两个结构变量。
我自己做数据架构,看这套东西眼熟得很,做过流式数据管道的应该都有同感:
- messages 是一个 append-only 的事实日志,每条消息是一个事件(用户说了什么、模型回了什么、工具返回了什么)。
- 每轮 build prompt 是对这个日志做一次全量重放(replay),把所有事件拼成完整上下文。
- KV cache 是重放操作上的物化视图(materialized view),缓存日志前缀的计算结果;日志一追加、前缀变长,命中率就下降、触发重算。
- 「只增不减」对应不可变事实表(immutable fact table):改历史等于改上下文,模型行为会变得不可预测,所以只追加不修改。

token 成本的结构性来源就全在这条链上:每次历史追加 → prompt 变大 → cache 前缀变长 → 命中率下降 → 计算量上升。这不是模型的问题,是架构的物理代价。区别只在于:数仓里重放是为了重算指标,Agent 里重放是为了让一个没有记忆的模型「看见」完整上下文。
想通这层,你就不会再把省 token 理解成「少打字」。真正能动的杠杆只有两个:前缀稳定性(别乱切话题、别中途改 system / CLAUDE.md,保住 cache 命中)和历史增长速度(能 grep 别 read,别让工具往历史里灌垃圾)。 后面几篇讲的每一招,本质都在拨这两个变量。

收口 + 下集钩子
Claude Code 好用,我的判断是七成来自工程层——这是体感,不是实验测出来的精确比例,但方向我很确定。5 步循环 + 工具调度 + 上下文管理,这三样把一个每轮失忆的无状态 LLM,缝成了一个能连续对话、能调用工具、能记住上下文的 Agent。模型本身当然重要,可没有这个工程层,模型就是一台只能回答单轮问题的打字机。
再撂一个可以打脸的判断:未来 12–18 个月,Agent 框架的竞争会从「拼模型」明显转向「拼上下文工程」——谁把前缀稳定性和历史增长这两个变量管得好,谁的单位任务成本就能低一个量级。这事我赌得挺死:就跟 2010–2015 那波数据库选型一样,最后拼的不是谁引擎快,是谁的 schema 和索引设计得稳。
下集预告:这条「只增不减」的历史,30 轮 coding 会烧穿 545K token。真账单到底在 system 还是在你的输入?S02 拆一次真实会话的 token 账单,告诉你哪一步最贵,以及 Compaction 是怎么止血的。
互动题:去翻你最近一次 Claude Code 长会话,数数从开始到 usage 报警大概聊了多少轮,再看看那个会话的 messages 数组里 tool_result 占了多少 token。我赌你会发现,真正吃掉额度的不是你打进去的字,是工具吐回来的那一大堆。
本系列每周两更,跟着拆完,你会对每一次回车背后的开销心里有数。卡在哪个点,评论区告诉我,我挑高频的写进后面几篇。
我是做数据架构的,在公众号「炼丹炉手记」用工程师的较真劲儿实测 AI 工具的真实 ROI——真省钱、真赚钱,还是智商税。工程拆解之外的,都在那边。
本文为 AI 辅助创作。
本文首发于知乎:阅读知乎原文 →